
(TF)² #15 – AI-årskrönika 2024/25 – Vad händer egentligen?
Året som gått har levt upp till världens högt ställda förväntningar på AI-utveckling. I alla fall har det levt upp till mina. De enorma transformerbaserade neuronnäten har blivit både snabbare och smartare, samtidigt som de i större utsträckning lagt till mer så kallad multimodal funktionalitet - alltså att samma system förstår text, ljud, bild och även strömmad video. AI är så mycket mer än bara den generativa AI, eller GenAI, som är vad världen i stort ser mest av nu. Samtidigt kan vi inte förneka att det är just inom generativ AI som tempot är högst, så denna artikel handlar nästan uteslutande om händelser i GenAI-världen.
Den som är sugen på en nostalgitripp kan, som en digital variant av att botanisera i gamla LP-skivor, läsa förra årets årskrönika här.
De vulgärt stora språkmodellerna
Hur mäter man egentligen hur bra en språkmodell är? Ett sätt är att göra som Chatbot Arena och låta folk blindtesta svar och se vilket de gillar bäst. Detta har dock vissa nackdelar. Bland annat orkar folk inte ha långa realistiska dialoger i dessa tester, utan testar oftast sina små kluriga specialfrågor. I stället föredrar jag nu Livebench som lanserades under sommaren 2024. Livebench har hemliga tester som kontinuerligt uppdateras för att språkmodellerna garanterat inte ska ha sett dessa prov i förväg.
En språkmodell är så generell att det finns många kategorier för dem att vara duktiga på. Livebench mäter
Resonerande
Programmering
Matematik
Data-analys
Språkförståelse
Förmåga att följa instruktioner (IF i tabellen)

Alldeles i topp har vi två varianter av en resonerande modell (LRM - Large Reasoning Model), o1. Dessa räknar vi inte till stora språkmodeller (LLM), så låt mig återkomma till dem senare.
Fram till i slutet på november så dominerades dessa benchmarks av Anthropics språkmodell och chattbot: Claude 3.5 Sonnet. Denna släpptes i juni och var ett stort steg framåt. De har dock inte varit öppna med vad de gjorde för att ta detta steg. I stället har de lovat att göra samma sak med sin största modell - Opus 3. Detta har ännu inte skett, så det är fortfarande oklart om Anthropic hade tur med Sonnet 3.5 eller om de kommer komma med nya marknadsledande modeller under 2025.
I förra årets krönika så frågade jag var Google håller hus. I november och december har de äntligen kommit med svaret - de var bara sega på att komma i gång. Till och med deras lilla modell, Flash, slår Claude och ChatGPT. För de som följer Chatbot Arena så leder Googles Gemini även där. Deras generella marknadsföring och hype är dock mycket sämre än OpenAIs, så utanför en liten skara entusiaster så vet ingen om att OpenAIs språkmodeller är (tillfälligt?) omsprungna av 2-3 företag.
För var återfinner vi då GPT 4o? Jo, på 12e plats, bakom bland annat två små kinesiska företag. För att vara rättvis mot dem så bör man nämna att de har flera egna fördelar. De har till exempel alltid varit bra på att leverera sitt API, så för programmerare är de lättanvända. När vi på Tenfifty har försökt använda Gemini för projekt så har API:et av någon anledning varit mer skakigt än OpenAIs. Dessutom var de i somras först ut med en riktig bra liten och snabb modell, GPT 4o-mini. Dessa mindre modeller är nästan lika bra som de stora, men mycket billigare och snabbare. Förutom att den förbättrade ekonomin i småmodellerna möjliggör fler affärscase så är de speciellt viktiga för resonerande modeller och agenter - mer om det senare.
Går vi nedanför Google på listan så ser vi hur det kinesiska bolaget DeepSeek tränat sin V3-modell, som släpptes 26:e december 2024, så väl att den mäter sig med de bästa. Extra intressant är detta eftersom den tränades på en hårdvarubudget på 6 miljoner USD, vilket är minst 10 ggr mindre än konkurrenternas. Kostnaden att använda den är också i skrivande stund 2% av vad det kostar att köra Sonnet 3.5.
DeepSeek V3 är alltså en fritt tillgänglig open source-modell precis som den mest kända öppna modellen Llama från Meta. Den största versionen av dessa modeller står sig väl mot konkurrensen från de rent kommersiella modellerna, men det är fortfarande ohanterligt jobbigt och dyrt att köra dessa enorma modeller på egen hand.
Apropå benchmarks så finns det en sak som Livebench inte testar - hallucinationer. Detta testas i stället av FACTS. FACTS lanserades i december av Deep Mind för att utvärdera hur väl modeller håller sig till fakta från den kontext eller det dokument som de har fått som bakgrundsmaterial. Den mäter alltså inte hur mycket språkmodellerna hittar på egna grejer när du ställer generella frågor utan källdokument. Att mäta generella hallucinationer är tyvärr komplicerat att göra i praktiken.

I topp på listan, precis som på de flesta andra listor just nu, bor Googles Gemini-modeller. Eftersom det är Deep Mind som ligger bakom testerna är det dock möjligt att man bör ta det med en nypa salt.
De resonerande språkmodellerna
Så vad är en large reasoning model? I förra årets krönika skrev jag Mindre modeller kan däremot svara snabbare och mer kostnadseffektivt, och möjliggör avancerade tekniker som till exempel ”tankekedjan” (Chain-of-Thought), där modellen stegvis planerar och resonerar. Detta har nu blivit högsta mode! Chain-of-Thought är alltså när modellen i stället för att svara direkt får lov att ha en intern tankemonolog innan den svarar. Detta gör att den till exempel kan fundera över olika sätt att förstå en fråga, olika sätt att lösa en uppgift och kan kritisera och förbättra sitt eget svar, innan den till slut sammanfattar ett svar till användaren. Precis som vi, så kan en dator vinna på att få fundera lite innan den svarar.
Varför behövs då modeller speciellt för att resonera? Förutom den naturliga anledningen att vi vill kunna låta dem välja hur länge de ska tänka så publicerade Apple i oktober också en forskningsartikel om benchmarket GSM som är ett av standarderna inom AI-forskningen. Appleforskarna gjorde sin egen variant av detta benchmark, där tal, namn och annat kunde bytas ut automatiskt för att generera nya frågor. De visade då att modellerna blir sämre så fort frågorna inte är exakt de som står i detta benchmark. Allra sämst gick det för språkmodellerna när forskarna lade till ovidkommande fakta till frågan. Då blev de förvirrade mycket enklare än en människa skulle bli. Denna övertygande och välgenomförda studie gjorde att jag personligen ändrade min inställning till att LLM:er verkar förstå mindre än vad de ger sken av.
Det tar alltså mycket längre tid och är dyrare att använda en LRM än en LLM, så det är inte lämpligt för alla konversationer. Det är också därför jag inte tycker att det ska mätas mot rena LLM:er, eftersom dessa kan göras om till LRM:er med dyrare och långsammare men bättre resultat. Förr lade man den delen utanför själva språkmodellen i ett eget ramverk som med egen prompting och logik löste detta. Sedan OpenAIs modell o1 från september 2024 så finns det dock modeller som bygger in själva denna loopen i modellen för att få det ännu bättre och mer effektivt.
OpenAI släppte två LRM:er, dels o1, baserad på GPT 4o och dels o1-mini som baseras på den snabbare GPT 4o-mini-modellen. Här hände dock något intressant - eftersom mini är snabbare men lite dummare så hinner den tänka fler ord på samma tid som 4o och i bland visar det sig viktigare att få resonera länge än att vara smart. o1-mini lyckas alltså bättre på vissa benchmarks, även om den oftast ligger efter vanliga o1.
Google noterade detta och i december 2024 så visade de upp Gemini Flash Thinking, som är en liknande modell med inbyggd CoT baserad på deras snabba modell, Flash. Min första förutsägelse för 2025 är att Anthropic kommer släppa en egen CoT-modell baserad på Sonnet eller Haiku (deras minsta modell).
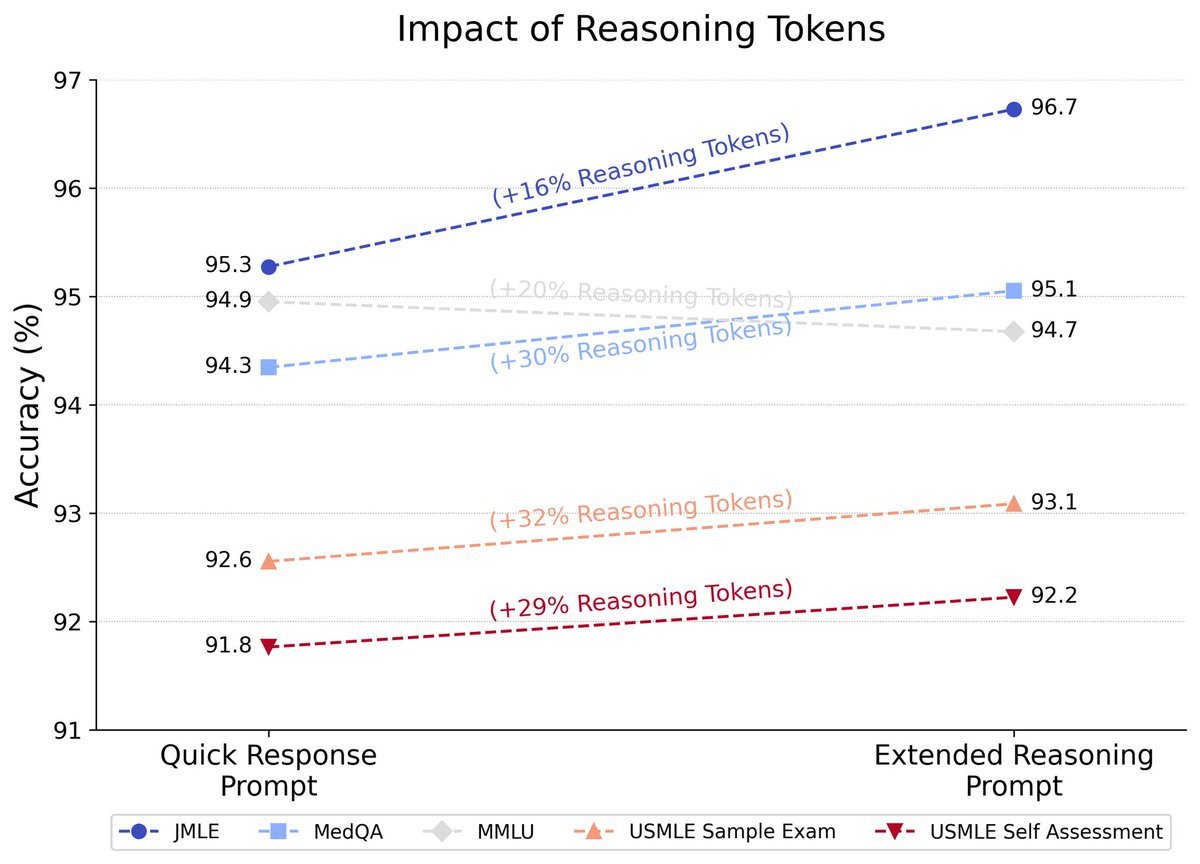
Ju mer tid, pengar och ord (“Reasoning Tokens” i grafen ovan är alltså hur många ord som modellen får tänka innan den svarar) som man lägger på ett svar desto bättre blir det. I en studie från november på o1-preview (den enklaste LRM:en) så blir resultaten på de fyra största medicinska problemuppsättningarna bättre när den får resonera än den svarar direkt. MMLU är inte ett medicinskt benchmark, utan ett generellt benchmark. Att den inte förbättras bortom ca 95% kan tyda på att några av svaren där helt enkelt är fel eller tvetydiga frågor.
LRM:er är dock inte bättre på allt. Bara för att du resonerar längre så får du till exempel inte automatiskt bättre faktagrund. Titta längst ned på FACTS-tabellen ovan för att se att hallucinationerna snarast försämras av o1.
¿Dónde está AGI?
I december hände dock något ännu viktigare - vi fick se testresultat på o3, OpenAIs senaste LRM. Den fungerar på samma sätt som o1, men den är bättre och de kan köra den mycket längre. För tester som rör mjukvaruutveckling så höjde den o1:s poäng från 49% till 72% rätt. På programmeringstävlingsproblem så höjde den sig till att bli lite sämre än plats 100 på världsrankingen för mänskliga programmerare. På Frontier Math, ett test på riktigt svår matematik, så hade ingen AI tidigare fått bättre än 2% rätt. o3 fick 25%... Den lyckades också bra på ARC-testet som är ett slags IQ-test med mönsterigenkänning där människor generellt är mycket duktigare än AI-modeller. Nackdelen med o3, förutom att den inte är släppt än, är att för att nå dessa resultat har de låtit den resonera riktigt länge. I vissa fall kostade en enda fråga 3440 USD att köra.
Är o3 AGI än då? AGI betyder alltså artificiell generell intelligens och handlar om att kunna göra alla typer av tänkande som människor kan göra. Trots att resultaten ledde till skrik om detta från de som gillar att skrika om sådant så är o3 inte i närheten av AGI. Den mest uppenbara grejen som saknas är att den inte kan lära sig från erfarenhet eller minnas - en förmåga som även de enklaste organismer har. Ben Goertzel, som är en av de som myntade begreppet på den första AGI-konferensen 2008, säger också att o3, likt alla språkmodeller, är betydligt sämre än människor på att extrapolera till nya situationer. Den är enligt honom endast bra på att interpolera och minnas liknande situationer. Jag själv är kluven på just denna punkt. Extrapolering är viktigt och något av det svåraste man kan göra, men i någon bemärkelse (som jag kanske får skriva en egen artikel om) så är kanske att extrapolera endast att interpolera på en ovanliggande abstraktionsnivå.
Men gör nåt själv då - Agenter!
I en BreakIt-artikel från sommaren 2023 skrev jag att agenterna är det som kommer härnäst. System som inte bara pratar utan också kan agera: Agenterar agerar nämligen. Det är mycket mer användbart med en assistent som kan göra saker åt dig i stället för att bara berätta vad du ska göra. I enklaste fallet handlar det om att söka upp och sammanställa information, men i mer avancerade fall så ska de till exempel kunna lösa datorproblem eller använda dina program automatiskt. Jag trodde nog då att det skulle gå lite snabbare än det gjort, men 2025 är upplagt för att bli agenternas år. Det säger bland annat Nvidia och Deep Minds grundare Demis Hassabis.
Agentiskhet, alltså att på någon skala uppvisa de olika delar som behövs för att agera självständigt, blir allt mer populärt som buzzword. Det har också under hösten blivit allt mer populärt att släppa sådana features. Anthropic var först ut, med ett API som kan titta live på din desktop och även kan interagera med den efter att ha frågat om lov.

Bilden visar Nvidias diagram över vad en agent bör innehålla. Den bör kunna minnas saker, den bör vara knuten till verktyg (alltså externa program) och den bör kunna planera för hur dessa verktyg ska användas för att uppnå vad användaren har bett om. Oftast finns inte alla dessa komponenter, eller så finns de bara i begränsad form. Då kan vi prata om grader av “agentiskhet”, alltså att ett system har fler agentkomponenter än vad språkmodellen har inbyggt.
I december visade Google många av sina idéer kring agenter som är integrerade i din vardag:
Deep Research kan ge sig ut och googla och sammanställa information åt dig kring något ämne. Det tar flera minuter för den att färdigställa informationen, så något helt annat än en ren chattbot, men mycket användbart för vissa ändamål. Jag testade att sammanställa de största AI-händelserna för 2024 och fick detta dokument tillbaka. Mycket bra tyckte jag! Tyvärr gjorde jag det när denna artikel var nästan färdigskriven, men det fick mig faktiskt att komma på några samhällssaker som jag missat som jag ville ha med. Jag har markerat detta senare i texten. Det bör även noteras att Perplexity är en tidig aktör kring att söka och sammanställa data med LLM, men de siktar in sig på snabbare svar än de genomarbetade rapporter som Deep Research försöker lösa.
Gemini Realtime Streaming kan testas här och möjliggör att du kan ha en kontinuerlig röstkonversation med en LLM samtidigt som den får se din skärm eller kamera. Detta är inte agentiskhet i sig, men kommer bli ett viktigt sätt att integrera AI-assistenter i din vardag.
Project Astra slår ihop flera komponenter till ett koncept som ligger i mobil eller augmented reality-glasögon och ser vad du ser. Den har också integrerat verktygsanvändande, vilket i detta fall betyder att den kan använda bland annat Google Search och Google Maps för att svara på frågor eller måla information på skärmen. Dessa glasögon är på väg som prototyp hävdar Google, men i dagsläget finns det inget att testa.
Det är viktigt att den generativa AI:n utvecklas bortom att allting drivs med chatt. Samtidigt som att grundtekniken och möjligheterna utvecklas så måste IT-industri och startups bli bättre på att komma på nya sätt att samarbeta med GenAI. Det är först när vi kommer på hur verktygsintegrationen ska ske så sömlöst och smärtfritt som möjligt som värde uppstår. Jag vill inte att jag antingen gör allt eller att en AI gör allt åt mig - riktig kvalitet kommer från samarbete. Här tycker jag att Google ligger i framkant, med fullt av små experiment kring hur man ska jobba och leka med till exempel bild, video, musik och programmeringskod. De flesta av experimenten är tyvärr inte tillgängliga i EU.
Samhälle
Samhället i stort blir allt mer påverkat av det som en gång i tiden endast var ett obskyrt intresse. Världen är stor och för att inte göra denna redan allt för långa artikel allt för längre så blir det en punktlista på språkmodellsmanér:
Både nobelpriset i kemi och fysik gick till AI-forskare. Det är dock värt att påminna om att inget av priserna gick till det vi kallar generativ AI. Det finns mycket annan viktig AI - i en nära framtid kommer till exempel förmodligen reinforcement learning (RL) att smyga in mer i vår vardag. Det är inte en modig förutsägelse att tro att det kommer bli fler nobelpriser med AI-krydda i framtiden.
Den svenska AI-kommissionen släppte sin rapport i förtid, eftersom de säger att det är så viktigt att Sverige börjar agera.
Det verkar inte hända så mycket kring frågan om upphovsrätt på det en AI läser under träning och vad som händer om den producerar något som inkräktar på upphovsrätt. I början på november så avvisades i alla fall den stämningsansökan som Raw Story Media och AlterNet lämnat till OpenAI. Domaren skrev att de målsägande inte kunde visa någon konkret skada och att språkmodeller skapar nytt innehåll baserat på vad den lärt sig snarare än kopierar text direkt.
Deep Research tipsade om faktoiden att en tredjedel av alla amerikaner har experimenterat med GenAI, men endast 6% av företag använder det i sin verksamhet.
Deep Research påminde även om att EU-lagstiftningen AI Act faktiskt klubbades igenom, även om det inte blir lag förrän 2026. Det har pratats om AI Act så länge att jag glömde att det faktiskt beslutades på riktigt först i år.
Slutligen tipsade Deep Research även om att brottslingar har börjat använda allt mer deepfake för att lura sina offer. En anställd i Hong Kong betalade ut 25 miljoner USD, lurad av en deepfake-video. Skurkar har dessutom börjat med "virtuella kidnappningar" med fejkad information för att övertyga anhöriga om att någon är kidnappad och på så sätt få en lösensumma.
2025
Vad kommer sammanfattningsvis att hända 2025?
Google har nu kommit igång och jag tror inte att de släpper ledningen. Om ett år så är de fortfarande i topp på benchmarks.
Jag tror vi har nått väggen kring vad större språkmodeller kan åstadkomma. GPT-5 har blivit försenad till sisådär april 2025 och ryktet säger att den inte blir så mycket bättre. Framtiden ligger snarare i nya sätt att träna och i allting man bygger runt modellerna, till exempel resonerande modeller som OpenAI o3 och bättre minne. Just dessa modeller kommer få konkurrens från Anthropic och open source. Meta och DeepSeek släpper till exempel säkert något öppet alternativ.
På ett mer tekniskt plan så är feedback på output redan under själva träningen förmodligen en viktig nyckel för nästa generation, som redan påbörjats. Det gör att olika typer av djupare resonemang och programmering kan få feedback och lära sig under träningen. Även andra typer av användning av digitala verktyg kan ge snabb feedback redan under träning, vilket gör att modellen kan lära sig vad som fungerar genom att själv experimentera snarare än att bara kopiera vad andra gjort och sagt.
Agenter av olika slag, framförallt integrerat i webbläsaren eller till och med på operativsystemnivå, kommer bli mycket mer moget under 2025. Jag tror att jag om ett år kommer använda agenter som gör mer än att bara webbsöka i mitt dagliga arbetsflöde.
Video kommer fortsätta att bli bättre. Om ett år kommer det vara vanligt att se hobbyfilmer där scener har gjorts med video-AI, även om det inte kommer smyga sin in i professionell video än. Det stora problemet är fortfarande att det är svårt att få konsekventa personer och objekt mellan scener.
Slutligen vill jag citera det intressanta japanska bolaget Sakana AI: AI:ns framtid ligger i livslångt lärande där system kontinuerligt växer, anpassar sig och samlar kunskap över tid. Det kontinuerliga lärandet och anpassandet är det främsta som saknas i dagens generativa AI. Modellerna är kristaller frusna i tiden, som ännu inte kan följa med dig i vardagen och lära sig att bli din generella assistent.
Om du såhär i efterhand tänker att du hellre hade lyssnat på denna artikel som podd så kan jag varmt rekommendera sjätte avsnittet av Professorn och Galningen med mig, David Fendrich, och min podd-parhäst Amer Mohammed!
God fortsättning! 🥂