
(TF)² #16 – AI-årskrönika 2025/26 - Del 2: Vad händer?
I del 1 kunde ni läsa om vad som hänt tekniskt under 2025. Nu är det dags för den bredare bilden kring hur samhället reagerat, vad som fortfarande saknas, och vad jag tror kommer hända 2026.
Samhällspåverkan 2025
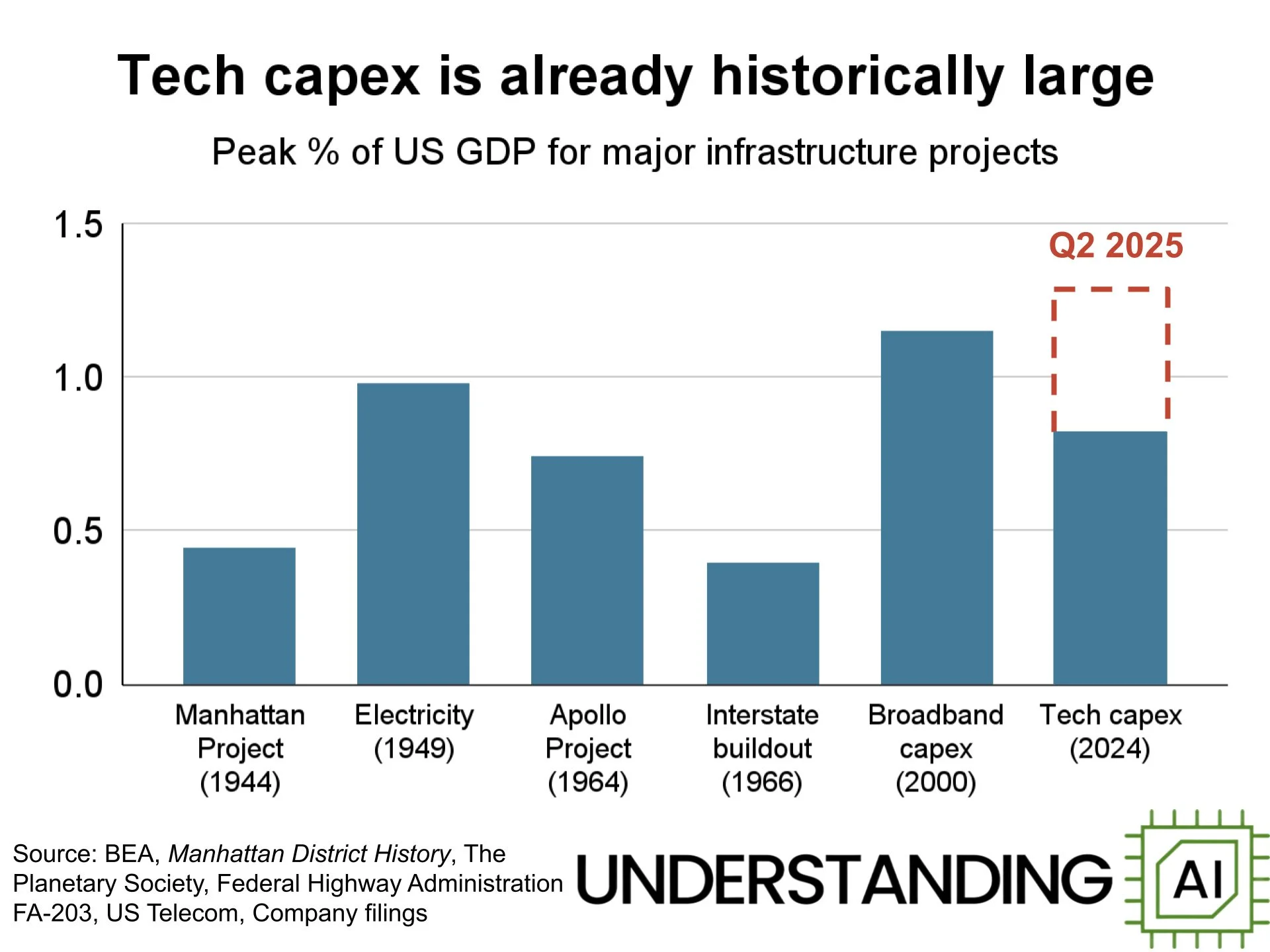
Redan i somras var de totala AI-investeringarna större än något annat jämförbart projekt, justerat för GDP och tempot på investeringarna planeras öka.
Reglering
EU:s AI Act började stegvis att gälla. I februari trädde de initiala förbuden mot vissa AI-system i kraft, och i augusti kom reglerna för generella AI-modeller. Det är ett ramverk i nivåer, vissa användningar är helt förbjudna, högrisk-användning kräver strikta krav, resten är mer fritt. Det påverkar även företag utanför EU som vill verka i EU.
I USA gick det åt andra hållet. Trump drog tillbaka Bidens AI-order redan första dagen som president och har sedan dess fokuserat på att blockera delstatlig reglering med argumentet att 50 olika regelverk stryper innovation. USA har dock ingen nationell reglering än. Denna diametralt motsatta hållning ledde till att USA under sommaren satte press på EU att mildra reglerna. Detta utreds just nu i ett förenklingspaket. Det föreslås bland annat att kraven för högrisk-AI ska skjutas upp till augusti 2027, att fler sorters data ska vara ok att träna på och att reglerna generellt måste bli "enklare och mer innovationsvänliga". En omröstning förväntas ske under våren 2026.
Kalifornien gillar att göra på sitt sätt, så de hittade ändå en väg framåt. Efter att Newsom vetoade den breda SB 1047 förra året kom i stället SB 53, "Transparency in Frontier Artificial Intelligence Act", som är mer fokuserad. Den gäller endast företag med över $500 miljoner i årlig intäkt och modeller tränade med mer än 10^26 FLOPS. Krav på transparensrapporter, säkerhetsprotokoll, incidentrapportering och whistleblower-skydd. Första delstaten att direkt reglera de företag som uttryckligen siktar på att en dag nå den vagt definierade termen "AGI", artificiell generell intelligens.
"AI slop" och informationslandskapet
En annan typ av samhällspåverkan är mer smygande. I slutet av december publicerade Kapwing en studie som visade att 21-33% av videorna som nya YouTube-användare ser i sitt flöde är "AI slop" – lågkvalitativt, AI-genererat innehåll skapat för att farma visningar snarare än att säga något meningsfullt. Situationen är liknande på musikplattformar som Spotify och Deezer.
Hundratals kanaler som enbart publicerar AI-genererat innehåll har tillsammans dragit in 63 miljarder visningar och 221 miljoner prenumeranter. Kapwing uppskattar att de genererar $117 miljoner årligen. Den mest framgångsrika, Bandar Apna Dost från Indien, har 2 miljarder visningar på videor som visar en digitalt genererad apa i emotionella situationer.
"AI slop" blev av förklarliga skäl årets ord enligt både Merriam-Webster och Australiens nationella ordbok.
Allt AI-genererat är inte heller AI-sörja. De flesta svenskar har nog de senaste veckorna hört talas om Jacub som i Sverige släppte hitlåten “Jag vet, du är inte min”. Det är rätt säkert att AI användes i framställningen av den, men vi vet inte hur mycket. Den fullt AI-genererade countryartisten Breaking Rust har ca 2,4 miljoner månatliga lyssnare på Spotify och det är rimligen för att folk faktiskt tycker om musiken. Liknande siffror har också pop/rock-bandet The Velvet Sundown. Kvaliteten har ökat markant - följ länkarna och lyssna själv!
Den legendariske cynikern H.L. Mencken skrev en gång “Democracy is the theory that the common people know what they want and deserve to get it good and hard.” Till viss del är AI-sörja vad användare vill ha. Algoritmen hade inte belönat det om det inte gav interaktion. Min favorit-AI-analytiker Zvi Mowshowitz hävdar att inte gäller bara AI slop, utan att även "Misinformation continues to be demand driven, not supply driven".
I grunden är detta bara ett av tusen ställen där samhällets strukturer inte är redo för att tillgången av saker som kan skapas med AI ökar dramatiskt. Man har till exempel kunnat photoshoppa digitalt i årtionden och manuellt mycket längre än så, men det är först nu som folk orkar använda Grok för att konstruera avklädda bilder på kvinnor mot deras vilja.
De positiva grejerna då?
Som med alla andra förändringar så tenderar nyheter att fokusera på det negativa, men det finns såklart positiva samhällseffekter också. AI har hjälpt till att snabba på forskning inom medicin, materialvetenskap, klimatmodellering och andra områden. Det har hjälpt till att demokratisera tillgången till kunskap och verktyg. Många småföretagare har fått hjälp med marknadsföring, design, och administration som de inte hade råd med tidigare. Dessa effekter kommer fortsätta att förstärkas under många år. Bland de ekonomer som tar förändringarna seriöst tror många att denna effektivisering på sikt kommer leda till en högkonjunktur på en nivå som vi historiskt aldrig sett!
Vad saknas fortfarande?
Kontinuerligt lärande
Jag avslutade förra årets krönika med ett citat från Sakana AI: "AI:ns framtid ligger i livslångt lärande där system kontinuerligt växer, anpassar sig och samlar kunskap över tid."
Ett år senare är detta fortfarande den största luckan. Modellerna är frusna efter träning. De kan inte lära sig från sina misstag mellan sessioner och modellens vikter förändras inte baserat på vad den upplevt. De minns inte vad ni pratade om förra veckan om det inte sparats som text och skickats med igen. Textminne har blivit vanligare i applikationerna för de stora språkmodellerna, men det är i grunden textsökning i sparade konversationer, inte riktigt lärande. Ett av de största problemen med att lära sig över tid har visat sig vara att alldeles för mycket av det som modellerna lärt sig i grundträningen glöms bort.
Det pågår forskning. Det finns idéer om LoRA-bankar (små delar i slutet på nätverket som kan uppdateras löpande), soft prompts som justeras över tid, och hypernätverk som genererar vikter. Men inget av detta är i produktion än. Frågan för 2026 är om vi får se ett seriöst första försök.
Promptinjektioner
När AI blir en vanlig del av vår digitala infrastruktur blir säkerhet allt viktigare. Agenterna kommer bli fler och få allt större tillgång till känslig information och kraftfulla verktyg. När tillräckligt många sådan agenter springer runt så ökar riskerna med prompt injection dramatiskt.
Promptinjektion, att lura en AI att följa dolda instruktioner inbäddade i data den läser, är fortfarande olöst. Säkerhetsforskaren Daniel Kang sammanfattade i somras läget med "we literally have nothing". I ett samhälle där AI är chattbottar är detta mest kuriosa. I ett samhälle där AI agerar med tillgång till din epost, din kalender, din bank eller företagsdatabaser blir det ett verkligt hot. AI-utvecklarna letar efter generella lösningar på promptinjektion och "jail breaking", men kanske krävs säkerhet i flera lager med antivirus-program speciellt för språkmodeller? Precis som vanliga antivirus-program så skulle dessa ha tillgång till en uppdaterad databas med de senaste jail breaking-metoderna, förmodligen kopplat till snabbare och dummare traditionella språkmodeller som inte kan hypnotiseras på samma sätt.
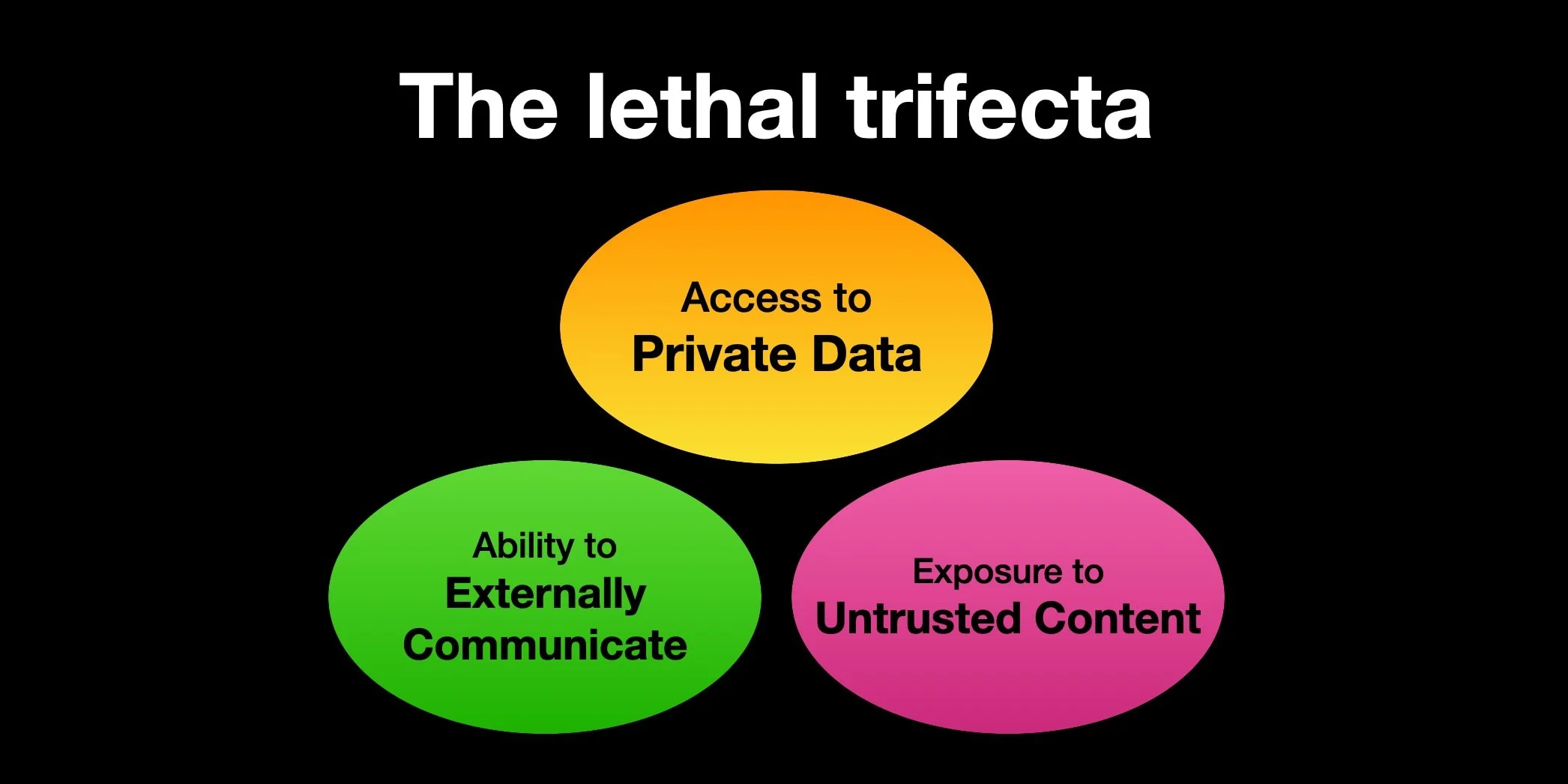
Simon Willison myntade i somras uttrycket “The lethal trifecta”, om vad man i mesta möjliga mån ska undvika när det kommer till AI-agenter.
Robusthet
Språkmodellerna är nästan uteslutande tränade att vara hjälpsamma assistenter, inte att vara misstänksamma mot en omvärld full av hot och människor du inte ska vara hjälpsam mot. Men att motstå bedrägerier och promptinjektioner är bara en sorts robusthet i verkliga världen.
När agenterna (som i sin tur är byggda på språkmodeller) förväntas utföra långa sysslor självständigt så kommer de förr eller senare göra något fel. Så är det med alla som ska utföra något komplicerat, även människor. Människor verkar dock vara mycket mer beredda på att validera och korrigera fel, ta ett större steg tillbaka och inte fastna i små omöjliga loopar. Till slut tröttnar vi och försöker lösa saker på något helt annat sätt. Eller nöjer oss med något halvdant och går vidare. Vi verkar också fortfarande behandla oväntade situationer, otydliga krav och saknade feedback-loopar bättre.
Även hallucinationer kan ses som ett robusthetsproblem. Det finns alltid en risk att man gör fel eller missminner sig när uppgifterna blir tillräckligt komplexa, så hallucinationer är inte i grunden ett AI-problem. AI-problemet kommer av att de, pga hur de är tränade, belönas för att chansa aggressivt. Det går att göra språkmodeller som har bra kalibrering kring hur sannolikt det är att de har fel i specifika fall. De bästa modellerna fortsätter att bli bättre på att inte hallucinera, men vi är fortfarande inte helt i hamn.
Dessa tillkortakommanden är förmodligen inte fundamentala problem med den tekniska arkitekturen. Min uppfattning är att när agenter blir allt viktigare så kommer just denna typ av träning bli uppdaterad för att göra dem mer robusta i fler miljöer. Det kan till och med bli en egen modell eller ett eget läge, som bland annat värderas mer på korrekthet än hjälpsamhet och som skiljer på input från en betrodd användare och generell omvärld.
Förutsägelser för 2026
"Ingen vet vad som kommer hända." hör jag ofta i min bransch. Men detta är inte en ursäkt för att ta på sig ögonbindeln och inte försöka se vad man anar vid horisonten. I de flesta situationer behöver vi ta beslut under osäkerhet och kvalificerade gissningar hjälper. De som gör lite mer snajsiga förutsägelser sätter procentchans på sina utsagor, men jag kommer nöja mig med att säga att jag tror att ca 6 av 8 slår in.
Teknik
1. Delvis autonom AI-forskning
Stephen McAleer, forskare på Anthropics Alignment Science-team, skrev nyligen: "I've shifted my research to focus on automated alignment research. We will have automated AI research very soon and it's important that alignment can keep up during the intelligence explosion". Jag tror att under 2026 kommer utvecklingen av de största AI-modellerna bli delvis autonom, inte i bemärkelsen att AI:n bestämmer allt, men att AI-system genererar hypoteser, kör experiment, analyserar resultat och föreslår nästa steg.
2. Första seriöst försök på kontinuerligt lärande
Inte "löst", men mer än en forskningsartikel. Åtminstone en beta-feature från ett stort labb som visar en icke-textbaserad uppdatering av kunskap baserat på erfarenhet. En av anledningarna till att jag tror detta är att Anthropics Sholto Douglas nyligen sade i en intervju att han tror att det blir löst på ett tillfredsställande sätt under 2026. Det är möjligt att det blir dyrt att ha separat lärande för olika användare, så det kanske inte slås på för allmänheten direkt. Det finns två typer av kontinuerligt lärande, dels att lära sig fakta och att lära sig att tänka och agera genom erfarenhet (reinforcement learning). Den andra typen är den riktigt kraftfulla delen, som också rör sig i gränslandet till självförbättring. Det är rimligen den första typen som blir aktuell nu, även om Nvidia precis publicerat forskningsartikeln Learning to Discover at Test Time med en modell som förbättrar sig erfarenhetsmässigt på matematik och vetenskap.
Trots detta är jag ganska säker på att vi inte får något som jag skulle kalla "digital AGI". Typ-2-lärandet kommer inte vara på plats och fenomenet som myntats "ojämn intelligens" (jagged intelligence) kommer fortfarande vara kvar. Modellerna kommer fortfarande vara väldigt bra på vissa saker och dåliga på andra och de kommer fortfarande ha tillräckligt stora luckor för att det inte ska vara robust att "släppa lös dem". AI-pionjärer som Yann LeCun säger att vi har blivit lurade över hur bra transformermodellerna är på text och programmering och att den ojämna intelligensen endast kan lösas med nya typer av så kallade världsmodeller. Jag tror personligen att även om det med hög säkerhet finns mycket bättre arkitekturer, så kommer vidareutveckling längs den nuvarande teknikkurvan vara tillräckligt för att kommande AI-agenter gör dessa modellförändringar mer eller mindre på egen hand.
3. METR-dubbleringstiden accelererar
METR står för "Model Evaluation & Threat Research". De är ett oberoende forskningsinstitut som i våras blev kända när de hittade något liknande Moores lag för AI-kapabilitet. De såg att det historiskt tagit sju månader för AI-modellerna att bli så mycket bättre att de klarar dubbelt så långa digitala sysslor med en viss (50 eller 80) procentandel lyckade uppgifter (mätt i hur lång tid det tar för en människa att utföra dem). Snarare än att utvecklingen under resten av året saktade ned så såg den ut att gå ännu snabbare. En teoretisk anledning att tro att kurvan är superexponentiell, alltså att dubbleringstiden minskar, är bland annat att AI snart kan hjälpa till med forskningen och redan hjälper till med programmeringen. Jag tror att under 2026 ökar hastigheten till att vi har 5 månader som dubbleringstid.
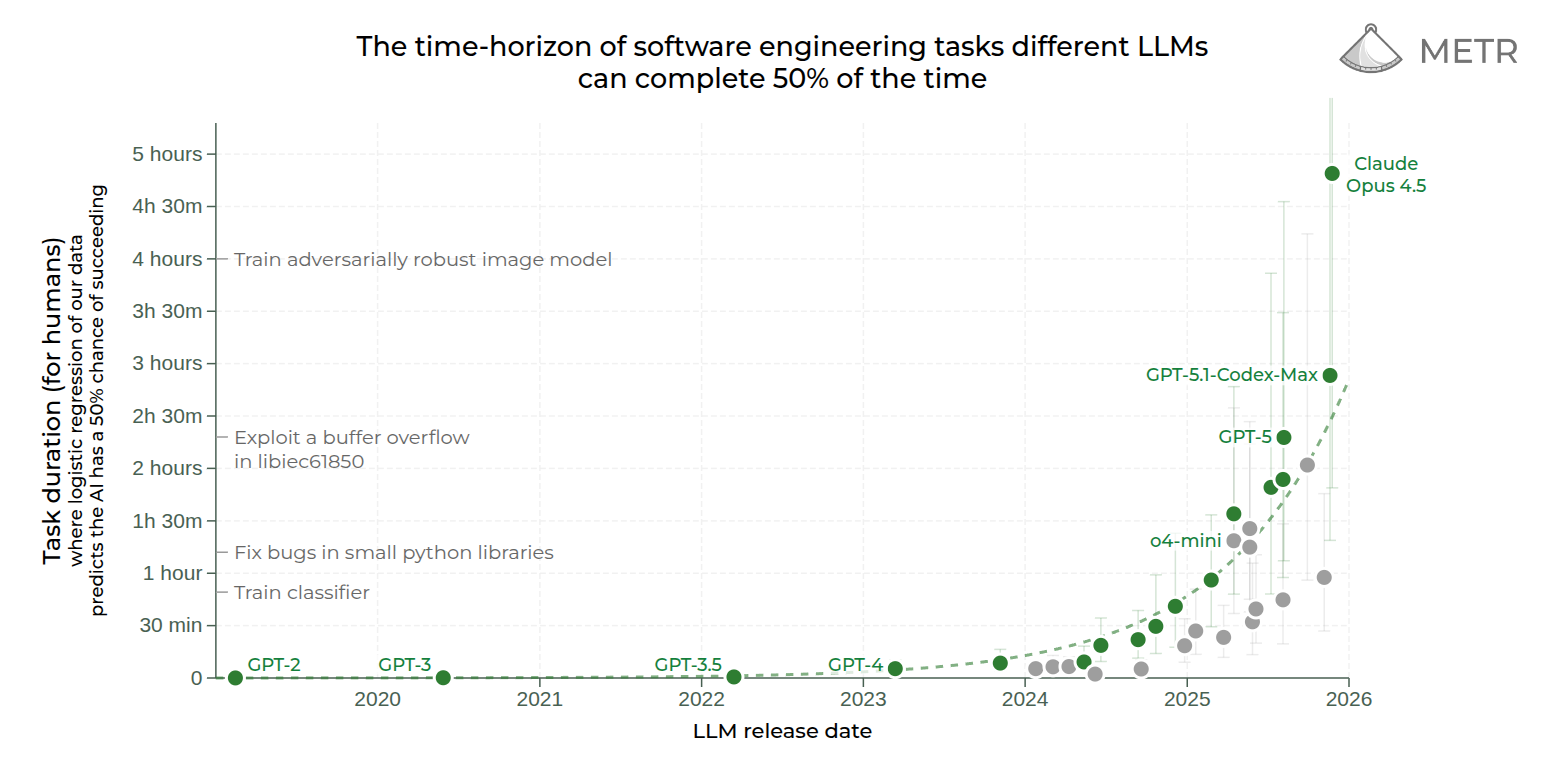
När man läser dessa kurvor är det viktigt att komma ihåg att det är stora konfidensintervall (de ljusa strecken), så exakt vilken modell som var bäst när, är inte så viktigt. METR har också för få uppgifter i sin databas som tar tillräckligt lång tid för människor, så nu när språkmodellerna har blivit så bra, så behöver de investera i större och svårare data innan framtidens AI kan testas.
4. Dubbelagenter
Någons agent blir hackad på ett sätt som får medial uppmärksamhet. Kanske en företagsagent som läcker konfidentiell data. Kanske en betalningsagent som luras att överföra pengar. Det tar förmodligen till hösten innan tillräckligt många agenter är i gång, men förhoppningsvis kommer det accelerera diskussionen om AI-säkerhet.
5. Diffusionsmodellerna slår igenom
Inception Labs har släppt den fantastiskt snabba språkmodell Mercury, som du kan testa här. Mercury är baserad på diffusion, en teknik som fram till nu endast använts för att generera bilder. Google har också en diffusionsmodell i sluten beta. Naturligtvis ligger den efter de bästa modellerna på de uppgifter som kräver mest intelligens, men samtidigt så kan de användas för att väldigt snabbt generera kod och svar på enklare frågor, till exempel som en del i en kodagent. Under 2026 så borde allt fler sysslor kunna skötas med diffusion och jag tror (och hoppas, på grund av användarupplevelsen) att detta integreras som en del av ett vanligt arbetsflöde.
Samhällspåverkan
6. Programmerare slutar skriva bokstäver
Vid slutet av 2026 kommer de mest effektiva utvecklarna i ett vanligt mjukvaruteam, som inte är förhindrade att använda extern AI, inte längre skriva bokstäverna i koden. De promptar, itererar, granskar, debuggar - men de skriver inte. Som jag skrev i förra delen så är till exempel uppfinnaren och huvudutvecklaren till Claude Code, Boris Cherny, redan där. För bara någon dag sedan skrev en av OpenAI:s största profiler, "roon", att även han slutat skriva kod. Det är stor skillnad på hur lätt det är för AI att vidareutveckla en ung kodbas och en gammal komplex, men med tillräcklig dokumentation om kod och projekt, samt förbättrad kunskap kring hur man använder dessa verktyg, så tror jag att även de komplexa kodbaserna faller.
7. Personliga AI-agenter blir "irriterande att vara utan"
För early adopters. Inte för alla. De som aktivt integrerat agenter i sitt arbetsflöde, kopplat till kalender, epost, anteckningar, webbläsare och transkribering, kommer uppleva att det är frustrerande att vara utan dem. Det är min egen målsättning att nå dit kring ca sommaren 2026, så jag har hud i spelet här.
8. Världen vaknar fortfarande inte
"Vaknar" i bemärkelsen att gemene man, media och politiker på fullt allvar diskuterar att utvecklingen inte verkar avta. Att vi inte kommer återgå till någon sorts post-hajp-normalitet. Att de stora strukturella förändringarna: arbetsmarknadsförändringar, samhällseffektivisering, maktförskjutningar och existentiella risker faktiskt kan inträffa. Det blir säkert mycket snack om AI i det amerikanska mellanårsvalet, men inte på fullt allvar. Overton-fönstret rör sig för långsamt.
Sammanfattningsvis
2025 var året då resonerande modeller blev mainstream, då AI fick guldmedalj i matematikolympiaden, då vajbkodning blev norm och då METR-horisonten nådde en halv arbetsdag. Jag ser fortfarande kommentarer på social media av typen "Jag ser fram mot att AI-hypen går över så att saker blir som vanligt igen". På gott och ont så får vi vänja oss vid att saker inte blir som vanligt igen.
En något senkommen God Fortsättning tillönskar vi er alla! 🥂